All images are clickable
Threading Player Updates
Back in
Jungle Update blog, I wrote about experimenting with batched processing of players on our servers. To summarize, I talked about how we needed to restructure code and start doing more operations in batches instead of on individual basis, and I showcased how it allowed us to leverage Burst and parallel job execution to speed up NoClip checks on the server.
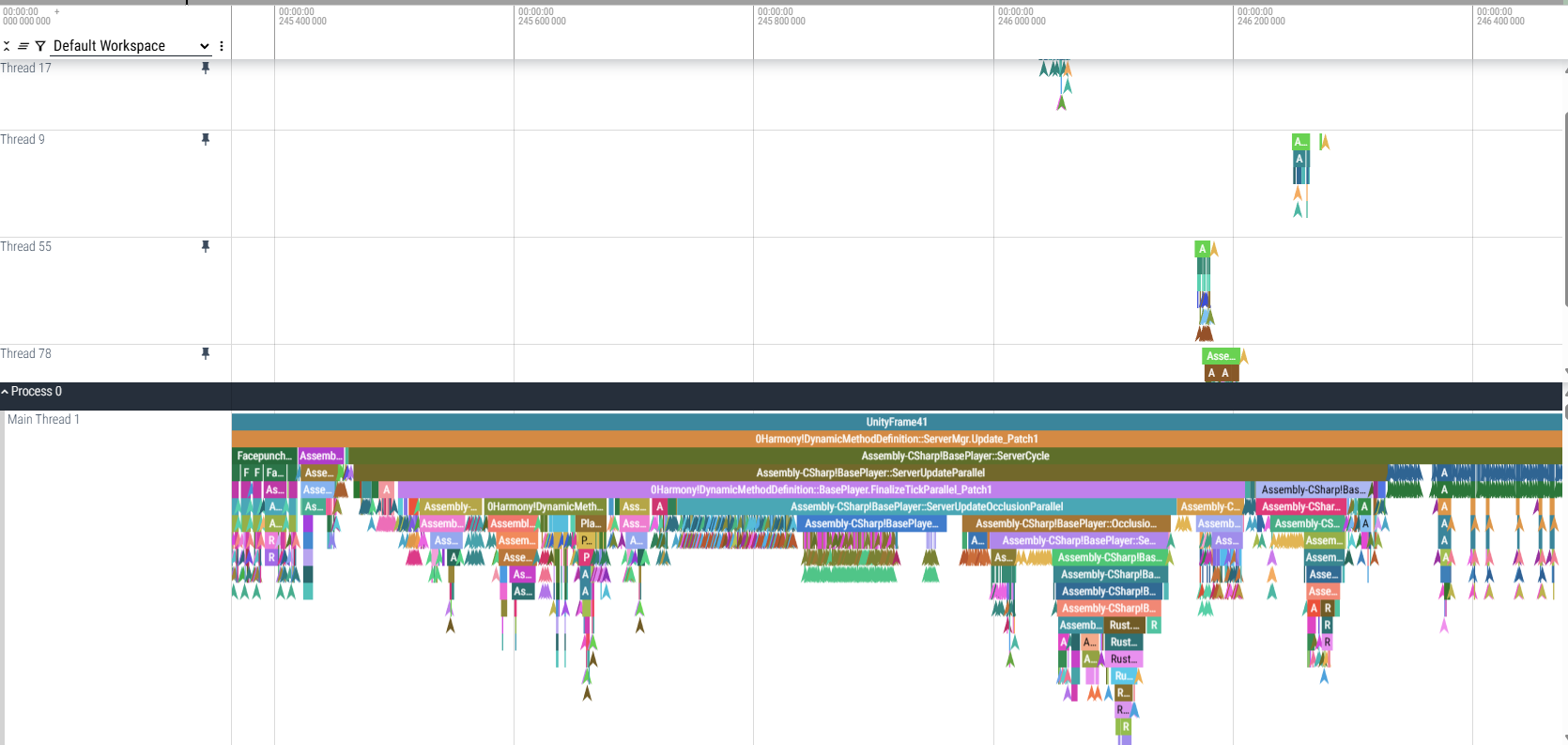
This update I'm taking it a step further - I've converted more parts of our player update code to batch/pipeline form, which allowed to clearly see dependencies between processing stages. This, in turn, confirmed which parts we can try to process in parallel on worker threads. As a result, we can now offload a bunch of player-related logic over to worker threads, speeding up the main thread:
Right now it's gated behind UsePlayerUpdateJobs 2 server variable, as an experimental mode. We've been running this on our EU Staging Server for a couple weeks to confirm that things are stable - and so far it's holding, but I don't have clear guarantees on how it will scale on high-population servers. In theory, thanks to these points:
- Faster server occlusion (more on that below)
- Avoiding redundant calculations of player state by using frame caches
- Use of managed threads for work offloading (sending entity snapshots and destroy messages have been converted)
I'm hoping that it'll allow the server to scale better with a higher player count and make player processing less of a bottleneck.
The plan is to roll it out gradually to release servers, while confirming server stability & performance - so far it's been developed in a lightly stress tested EU Staging, so I'm missing real world data. After roll-out is successful, I'll be able to identify further bottlenecks and work on expanding parallel processing.
Server Occlusion Optimizations
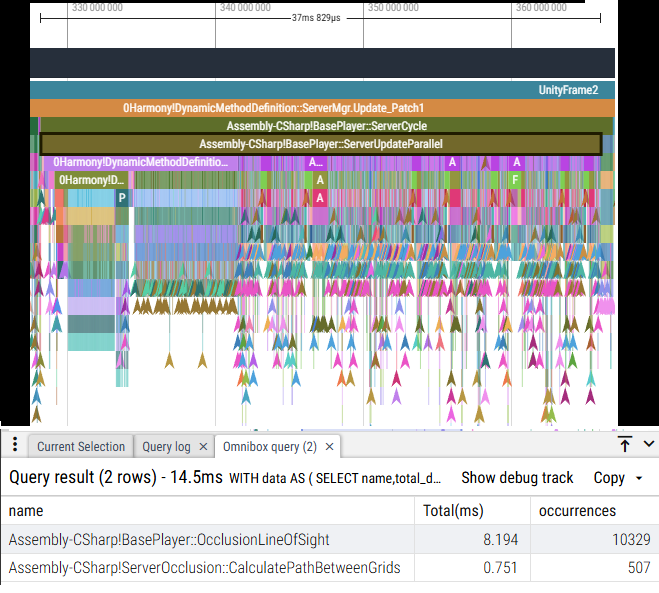
As part of the above rewrite I took a look at server occlusion, as I noticed that it has been running too many checks per frame. In addition to other problems, this caused server occlusion to eat up to 8ms in some cases, like bellow:
Having to process 10k occlusion queries for 350 players seems to be excessive, even if it eventually boils down to only 500 paths to check.
I've reworked the relevant code to benefit from the following improvements when UsePlayerUpdateJobs 2 is enabled:
- We now deduplicate occlusion queries - if player A and player B want to check for visibility of each other, it's enough to just check A->B
- We run occlusion queries in parallel
- We cache results of occlusion queries for the duration of a frame, allowing us to skip them throughout the rest of the frame
I'm hoping that the gains will scale with the player count and become substantial once we're testing with 350+ players.
Going Forward
The rewrite of player update allows us to see more clearly how the execution and data flow, but it's lacking further optimizations(aware of 1 bottleneck) and tuning (controlling worker batch sizes). My plan is to use the new telemetry to guide where to focus efforts as I continue to expand UsePlayerUpdateJobs further. I currently don't see a specific end in sight, as the more is converted, the more opportunities to capitalize on data/execution patterns we get.
If things go well for UsePlayerUpdateJobs 2 during this patch, it's likely the mode will be promoted to level 1, and a new experimental stage will begin.